
PDFの解説(簡単な部分のみ)
こんにちは。
エンジニア担当のYです。
営業から「何か技術ブログ書いて!」と言われてしまったのでつらつらと書いてみます。
重要:内容に多少齟齬があっても責任は負いませんので!
〜PDFファイルの読み方〜
はじめに
PDF(Portable Document Format)ファイルの読み方を、簡単な部分のみ解説します。
対象
- PDFファイルの表示・編集・作成ソフトを作成したい人
- PDFファイルの文法に興味がある人
解説対象のPDF
- Wordで適当に作成したPDFにしたファイル「テスト用文書.pdf」を使います。
※PDFあげられなかったのでJPGです…脳内補完してください。

解説内容
- ファイルの先頭を確認
- ファイルの末尾を確認
- xrefから各objectを確認
- 圧縮解除
- ページ
- テキスト、図形
- 画像
- フォント
ファイルの先頭を確認
まず、PDFファイルの先頭を見ます。
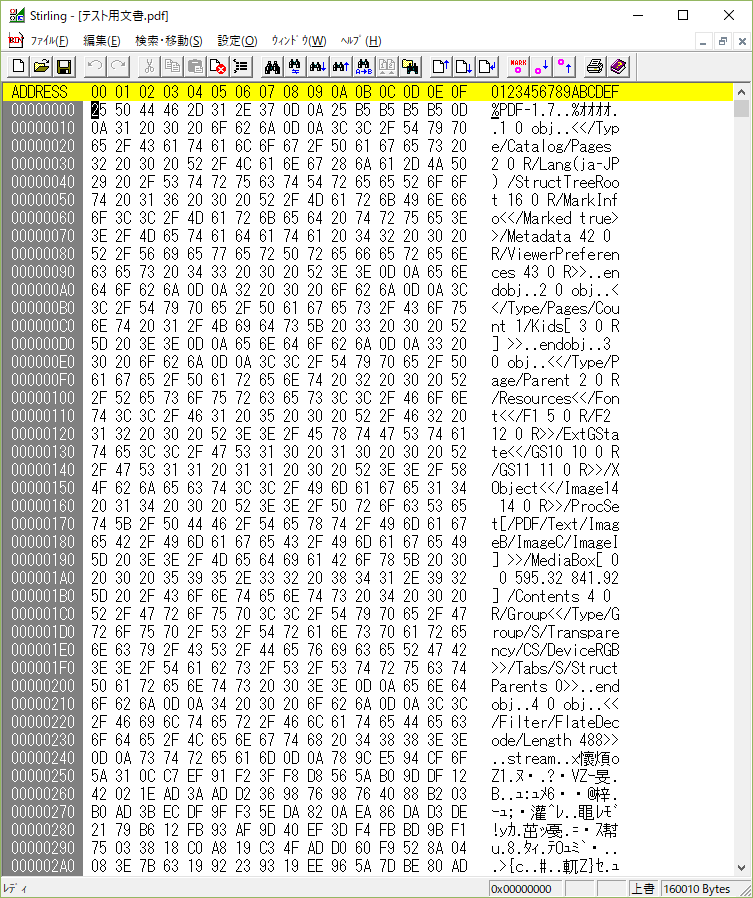
先頭には「%PDF-1.7」とあります。「-」の後はPDFバージョンですので、このPDFはバージョン1.7の文法で作成されたということです。
ですので、PDF1.7のリファレンスを見ることで全体を詳しく見ることができます。
あと、2行目はマジックナンバーで、バイナリファイルであることを示しているだけです。
ファイルの末尾を確認
ファイルの先頭を見てPDFであることを確認したら、末尾を見ます。正確には、「startxref」を末尾の方から探します。
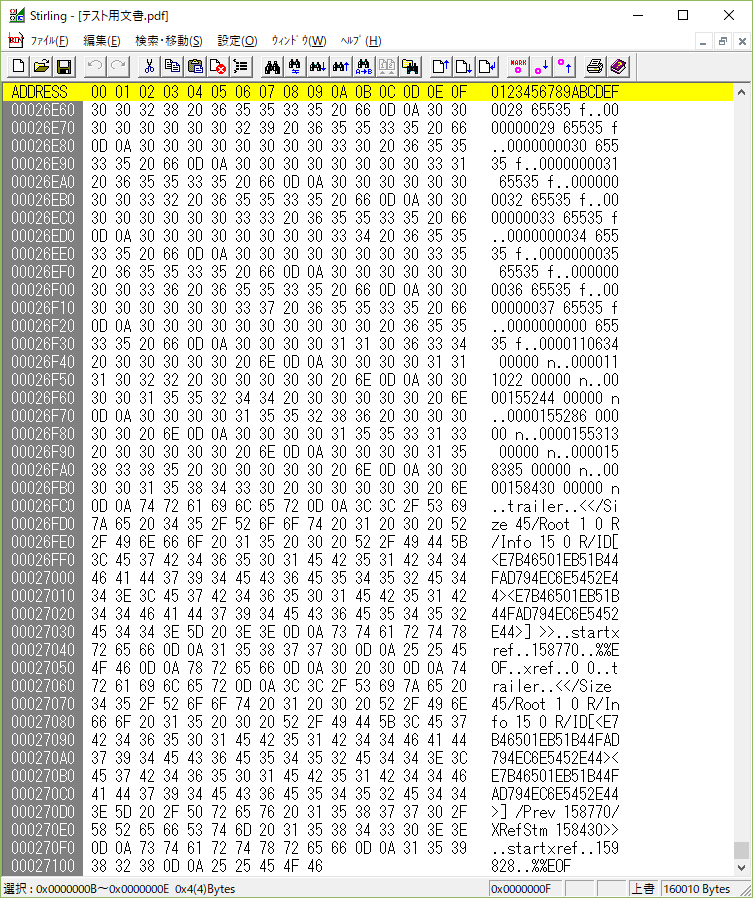
最後は「%%EOF」で終わります。
その前に、「startxref」「159828」があります。
なぜか「startxref」が2つありますが、通常は1つです。
編集するたびに、増えていくのですが、編集していない新規作成なのに2つあるのが不思議です。
WordのPDF作成機能が、1回編集するようになっているのでしょうか。
PDFは、1回作成後、編集した場合は、ファイルの最後に追記されていきます。もう使わなくなったObjectもそのまま残ります。ですので、編集するたびに肥大化します。
テキストを書き換えても、元のテキストはファイル中に残り、新たなテキストオブジェクトが末尾に追記されるだけです。
startxrefの次の「159828」はファイルの先頭からのバイト単位の位置を示しています。
つまり、ファイルの先頭から「159828」バイトの位置を参照しなさいということです。
xrefから各Objectを確認
ファイルの先頭から「159828」バイトの位置へ移動すると、「xref」があります。
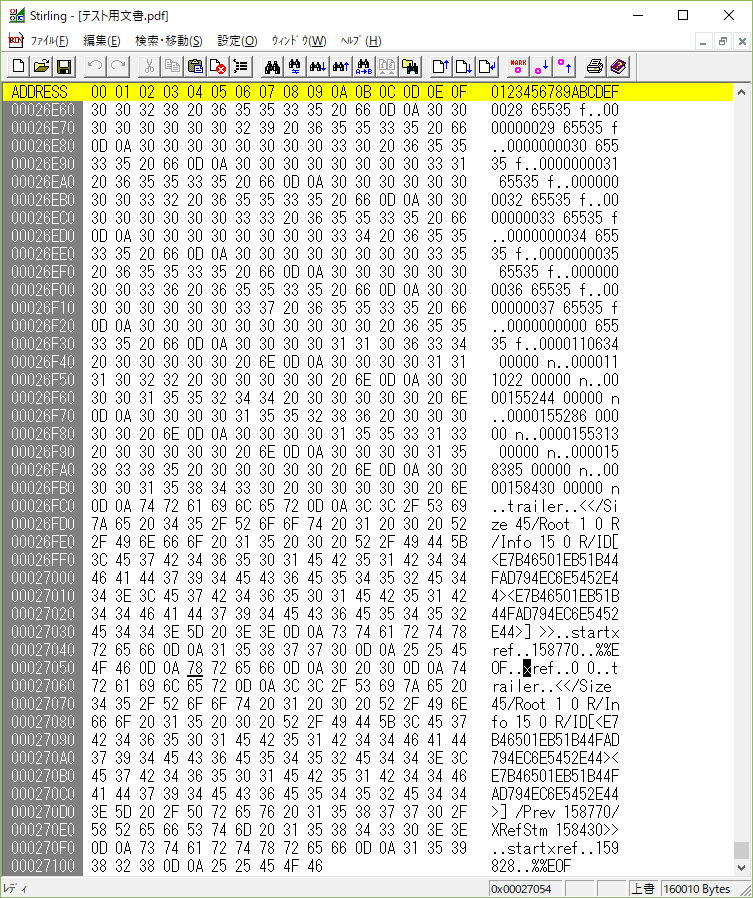
xrefの次の「0 45」は、Objectが0から始まって45個あるということを示しています。
そして、その次の「0000000016 65535 f」というような部分が45個あることが分かります。
これは、「0000000016」がその番号のObjectの開始バイト位置です。例えば、「0000000017」はオブジェクト番号1の開始位置が17バイト目であることを示しています。
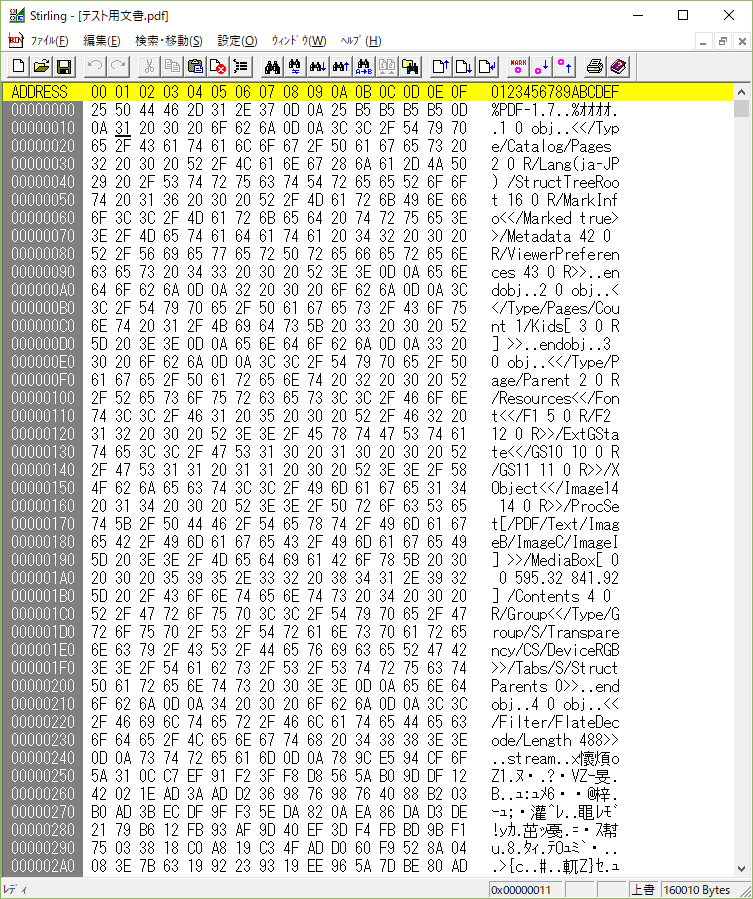
実際に17バイト目を見ると、「1 0 obj」の先頭になっています。同様に、1~44のオブジェクトの位置が分かります。
これで、各オブジェクトの位置が分かるようになりました。
さらに、「trailer」の下に「Root 1 0 R」「Info 15 0 R」というのがあります。
これは、オブジェクトの参照で、「Rootオブジェクトが 1 0 obj」「Infoオブジェクトが15 0 obj」であることを示しています。
Rootオブジェクトは、このドキュメントのカタログで、Pagesでページの管理をしています。
Infoオブジェクトは、このドキュメントの情報を格納していて、作成者、作成日などを見ることができます。
圧縮解除
各オブジェクトは「1 0 obj」のような書式で始まり「endobj」で終わります。
ただし、ほとんどが中を見てもわけのわからないバイナリになっています。それは、ZIPで圧縮されているからです。
「/Filter/FlateDecode」とあるのがそれで、これはフィルターに「FlateDecode」を使ってデコードしてください、という指示です。この圧縮を解除して分かりやすくします。
そのためのツールとして、PDFtkを使います。
次のようにコマンドを打ちます。
pdftk (対象ファイルのパス) output (出力ファイルパス) uncompress
これを行うと、ファイルサイズが2倍になりましたが、中身がわかりやすくなりました。
これでもバイナリになっている個所は、もともとバイナリだということです。フォントや画像などがそうです。
ページ
「1 0 obj」を見ると、「/Pages 2 0 R」があります。
これはこのドキュメントの全ページを管理するPagesオブジェクトが「2 0 obj」でることを示しているので、次に「2 0 obj」を見ます。
「/Kids [6 0 R]」が各Pageのオブジェクトの参照を表していて、「6 0 obj」が1ページ目であることが分かります。
ですので、次に「6 0 obj」を見ます。
これがPageオブジェクトで、見るべきは「/Contents 12 0 R」で、ページの中身は「12 0 obj」であることが分かります。
また、「/Image14 9 0 R」で、画像オブジェクトが「9 0 obj」であること、「/F2 10 0 R」「/F1 11 0 R」からフォントオブジェクトが2つあり、「10 0 obj」「11 0 obj」であることが分かります。
テキスト、図形
「12 0 obj」を見ます。
いろいろ書いてあって分かりにくいですが、テキストは「BT」から「ET」の範囲です。 「/F1 10.5 Tf」は、フォントの指定で、「F1」という名前付けしたフォントで、10.5ポイントの大きさで記述を開始する、ということです。
「1 0 0 1 85.1 729.96 Tm」は拡大縮小等の行列要素が並んでいます。 「[<03C403B703C60F3D0E0A097D>] TJ」が実際のテキスト文字です。16進の文字コードですので、4文字で1文字分になります。
ただ、このままではなく、変換をする必要があります。細かい説明は省きますが、「11 0 obj」からの「/ToUnicode 14 0 R」で「 14 0 obj」を見ます。beginbfcharからendbfcharの個所が、文字コードの変換表です。
つまり、下のようになります。
03C4→30C6 テ ,
03B7→30B9 ス ,
03C6→30C8 ト ,
0F3D→7528 用 ,
0E0A→6587 文 ,
097D→66F8 書
次に、「0.000008871 0 595.32 841.92 re」を見ます。これは、「re」が長方形を描く指示で、数字が「x y width height」です。
フォント
「11 0 obj」を見ます。いくつかのオブジェクトに分かれているのですが、「/DescendantFonts 13 0 R」からたどって、これがType0のCIDFontType2であることが分かります。
どんなものかは説明を省きますが、CIDは日本語用フォントです。
「17 0 obj 」を見ると、フォントの仕様がいろいろ書いてあります。その中で、「/FontFile2 19 0 R」から「19 0 obj」を見ると、これがフォントファイルです。
文書で使っていたのは明朝なので、これがフォントファイルの中身です。
ただし、明朝のフォントファイルすべてではありません。
PDFファイルサイズを節約するために、使用されている文字をもとに最低限の部分だけ取り出しています。
フォントファイルをPDFに格納していることにより、どのPCで見ても、同じ見栄えになるのです。
画像
「12 0 obj」の中の「/Image14 Do」が画像を描く指示です。
その画像自体は、「9 0 obj」を見ます。
「/Filter /DCTDecode」は画像がJPEGだということ(DCT=離散コサイン変換)を表しています。
「Height」「Width」が高さと幅です。streamからendstreamまでが、JPEGファイルそのものです。
最後に
PDFの主となる要素を簡単に説明しました。
圧縮を解除することで、中身がより分かりやすくなったと思います。あとは、リファレンスと突き合わせて、細かい文法を理解すれば、PDFの作り方、表示の仕方がわかるかと思います。
社会人になってC言語のプログラマー歴3,4年もあれば全体は無理でも各機能に絞れば作成・表示ともに実装できるようになるでしょう。(かなりきつかったですけど。)